




I. Introduction▲
On entend de plus en plus parler de P2P aujourd'hui, mais qu'en savons-nous vraimentô ? D'un cûÇtûˋ, de grands groupes d'industriels qui dûˋcrient l'emploi fait de cette technologie, quand ce n'est pas la technologie elle-mûˆme, et prûˋsentent les utilisateurs du P2P comme des dûˋlinquants systûˋmatiques. De l'autre, des gens de tous ûÂges, de tous milieux sociaux, qui assurent ne pas faire de mal et ûˆtre (presque) dans la lûˋgalitûˋ.
Quoi qu'il en soit, ce ne sont pas ces points de vue qui nous intûˋressent ici. Le but de ce document est de prûˋsenter les diffûˋrentes architectures du P2P aujourd'hui, ainsi que d'autres pistes qui sont actuellement en exploration.
II. Qu'est-ce qu'un P2P▲
L'acronyme P2P signifie Peer to Peer, soit en bon franûÏaisô : Pair û Pair. Il s'agit d'un moyen de partager des ressources, comme le propose par exemple le mode client/serveur.
Le P2P est une technique. Cette technique est utilisûˋe par de multiples applications. Par exemple le P2P est utilisûˋ pour le partage de ressources parfaitement lûˋgales, comme des logiciels open source (Linux, EDI, outils, etc. ) ou des versions d'ûˋvaluation par exemple.
L'utilisation de la technologie P2P pour des tûˋlûˋchargements non autorisûˋs est illûˋgale. Par exemple pour les fichiers musicaux, il existe actuellement de nombreux sites vous permettant de les tûˋlûˋcharger en toute lûˋgalitûˋ tout en payant les droits d'usage de ces fichiers, de sorte que les auteurs soient rûˋmunûˋrûˋs pour leurs crûˋations. L'utilisation du P2P pour tûˋlûˋcharger des éuvres non libres de droits, ou dont vous ne vous ûˆtes pas acquittûˋ des droits, est illûˋgale.
II-A. Comment partager de l'information▲
Lorsque l'on souhaite partager de l'information entre plusieurs ordinateurs, il existe de nombreuses solutions. Celle qui est la plus mise en éuvre aujourd'hui est le modû´le client/serveur.
II-A-1. Mode Client/Serveur▲
Rien de complexe dans cette notionô : si vous prûˋfûˋrez une image plus concrû´te, remplacez le contexte informatique par le contexte d'un restaurant, c'est identiqueô ;)
Les clients dûˋsignent les applications qui cherchent û exploiter des services proposûˋs par un serveur. Les clients ne disposent pas d'informations, mais sont capables d'aller en chercher. Par exemple, on peut citer les navigateurs web (Firefox, Internet Explorer, Mozilla, SafariãÎ), mais aussi les logiciels de courrier ûˋlectronique (mutt, outlook, thunderbirdãÎ), les clients FTPãÎ
Si vous avez un ordinateur branchûˋ sur un rûˋseau (Internet ou rûˋseau local), alors vous vous ûˆtes dûˋjû servi d'un client.
De l'autre cûÇtûˋ sont les serveurs. Souvent situûˋs sur des machines puissantes afin de pouvoir servir plusieurs clients en mûˆme tempsô ; ils ont l'information û disposition.
Un des gros avantages de ce mode client/serveur est sa relative simplicitûˋ de fonctionnement. En effet, une fois que vous avez l'information que vous souhaitez partager, vous ouvrez un serveur (un peu comme on ouvre un restaurant), et vous n'avez plus qu'û attendre les clients. Bien sû£r, ici, pas question d'attendre que quelqu'un rentre û l'improviste, il faut faire connaûÛtre votre serveur.
Ce mode permet surtout une grande simplicitûˋ des mises û jourô : chaque possesseur d'information la met sur un serveur (on parle alors d'upload d'une information, contrairement au download qui consiste û rapatrier les informations du serveur vers le client), et elle est disponible immûˋdiatement pour tout le monde.
Le problû´me de ce mode de fonctionnement est son coû£t. En effet, si un ordinateur un peu puissant suffit largement û traiter quelques requûˆtes simultanûˋes, dû´s que le nombre de requûˆtes devient grand, les serveurs (ordinateurs utilisûˋs uniquement pour fournir un type de service) doivent se multiplier, et la connexion rûˋseau doit ûˋgalement ûˆtre augmentûˋe, faute de quoi les performances (temps de rûˋponse du serveur) seront dûˋgradûˋes. Le pire des cas est un crash du serveurô : celui-ci n'est plus en mesure de rûˋpondre.
II-A-2. Le P2P▲
Une autre maniû´re de partager de l'information est de ne pas se servir de serveurs, mais de relier tous les possesseurs d'informations. Cela a pour avantage de supprimer les serveurs, qui sont des machines coû£teuses, car trû´s puissantes. En revanche, cela complique ûˋnormûˋment la notion de recherche d'informations.
Ce mode de partage de l'information est le P2P. On peut considûˋrer que chaque utilisateur d'un P2P est û la fois un peu client et serveur (nous verrons par la suite que ce n'est pas toujours exact, en fonction de l'architecture utilisûˋe). Une fois que le demandeur sait oû¿ est l'information qu'il dûˋsire, les deux ordinateurs sont alors en mesure de s'ûˋchanger directement des informations, sans plus devoir passer par une machine tierce, c'est-û -dire sans utiliser des ressources autres que les leurs.
II-A-3. Avantages de l'un par rapport û l'autre▲
Considûˋrons une entreprise. Pour des raisons de sûˋcuritûˋ ûˋvidentes, elle souhaite ûˆtre en mesure de sauver les informations, afin d'en disposer mûˆme si un ordinateur (quel qu'il soit) tombe en panne. Il est donc logique qu'elle s'oriente vers un modû´le client/serveurô : chaque employûˋ, une fois le soir venu, transfûˋrera ses donnûˋes sur un serveur, et une copie des donnûˋes du serveur sera effectuûˋe (ces opûˋrations sont automatiques et ne demandent plus d'intervention, rendant la tûÂche encore plus facile).
Par contre, il est certain que cela a un coû£t non nûˋgligeable pour l'entrepriseô : elle doit disposer de suffisamment de serveurs en fonction du nombre d'employûˋs, doit effectuer une sauvegarde quotidienne des donnûˋesãÎ
De mûˆme, cette entreprise ne souhaite pas que toutes les donnûˋes soient accessibles û tout le monde. Or il est plus facile de surveiller quelques serveurs plutûÇt que quelques milliers de machinesãÎ En outre, les logiciels P2P n'offrent que peu de protections et de confidentialitûˋ sur les fichiers ûˋchangûˋs, comme nous le verrons par la suite.
En revanche, le P2P a pour lui sa simplicitûˋ de mise en place et d'utilisation, ce que recherche un particulier. D'oû¿ un certain engouement pour ce type de technologie.
Pour ceux qui n'auraient jamais utilisûˋ un logiciel de P2P, voici ce que ûÏa demandeô : tûˋlûˋcharger un logiciel depuis le site qui a (gûˋnûˋralement) le mûˆme nom que le logiciel. L'installer en cliquant toujours sur suivantô¨ô . Double-cliquer dessus pour le lancer, et cliquer surô ô£se connecter". Ensuite, vous avez û votre disposition un mode de recherche, qui vous permettra de trouver ce que vous voulez. Il ne vous reste plus ensuite qu'û double-cliquer sur le fichier proposûˋ en retour de votre recherche, et attendre qu'il l'ait tûˋlûˋchargûˋ.
Certes, cela se passe bien ainsi. Mais alors pourquoi existe-t-il tant de logiciels diffûˋrentsô ? Et quelles sont leurs diffûˋrencesô ? C'est justement û ce type de question que le chapitre suivant rûˋpond. Ensuite, nous verrons le P2P sûˋmantique, avant de parler d'autres axes de recherches menûˋes sur le P2P.
III. Les architectures P2P▲
III-A. Les architectures centralisûˋes▲
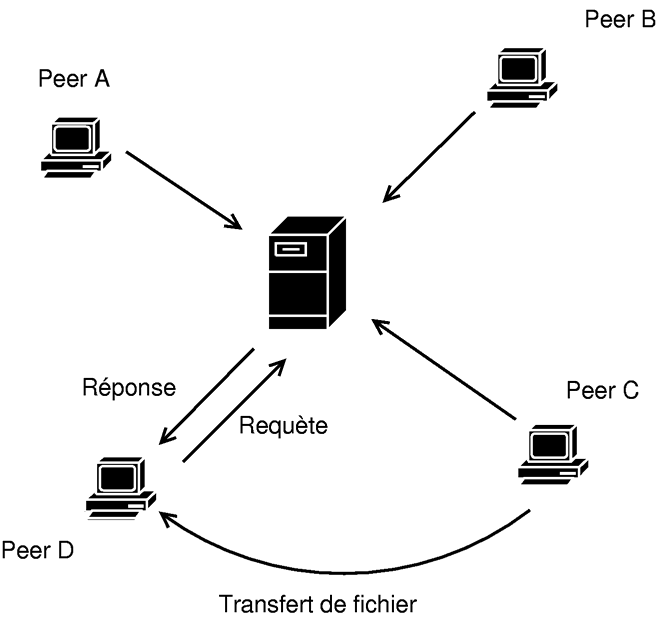
Le reprûˋsentant le plus connu de ce mode de P2P est sans doute Napster. (1) Cette architecture se compose d'un unique serveur, dont le but est de recenser les fichiers proposûˋs par les diffûˋrents clients. Contrairement au mode Client/Serveur, ce serveur centralisûˋ ne dispose pas des fichiers. Il dispose principalement de deux types d'informationsô : celles sur le fichier (nom, tailleãÎ), et celles sur l'utilisateur (nom utilisûˋ, IP, nombre de fichiers, type de connexionãÎ) Du cûÇtûˋ du client, rien de plus simpleô : une fois connectûˋ grûÂce au logiciel spûˋcifique, il peut faire des recherches comme avec un moteur classique. On obtient alors une liste d'utilisateurs disposant de la ressource dûˋsirûˋe. Il suffit alors de cliquer sur le bon lien pour commencer le tûˋlûˋchargement. Cette ûˋtape est complû´tement indûˋpendante du serveur, et reprûˋsente la seule partie P2P du logiciel.
Avantages
- Le confort d'utilisation est grand, puisqu'il n'y a pas de soucis de connexion au bon serveur.
- La recherche de document est facilitûˋe. En effet, le serveur est omniscientô : si un fichier est disponible sur le rûˋseau, on est en mesure de le savoir systûˋmatiquement.
Inconvûˋnients
- La sûˋcuritûˋ est le talon d'Achille de ce type d'architecturesô : il suffit de supprimer le serveur pour que l'intûˋgralitûˋ du rûˋseau soit inactive.
- Sensible au partitionnement du rûˋseau (serveur inatteignable) et aux attaques.
- Aucun anonymat n'est possible, puisque chaque utilisateur est identifiûˋ sur le serveur. Il est alors on ne peut plus facile d'ûˋlaborer des profils utilisateurs (diverses possibilitûˋs d'utilisationô : de la publicitûˋ ciblûˋe û l'identification des clients violant les protections intellectuelles par exemple).
III-A-1. Un exemple de rûˋseau centralisûˋô : Napster▲
Napster2 est le rûˋseau centralisûˋ par excellence.
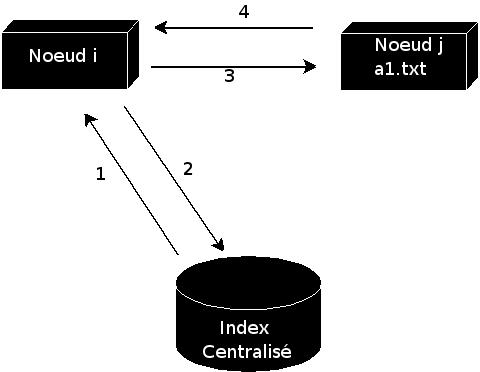
- Enregistrement du néud i. Ajout des fichiers de i dans l'index.
Demande du fichier ô¨ô a.txtô ô£. - Rûˋponse contenant les néuds disposant de ô¨ô a.txtô ô£.
- Demande directe de i û j pour tûˋlûˋcharger ô¨ô a.txtô ô£.
- Tûˋlûˋchargement de ô¨ô a.txtô ô£, et ajout dans la base de ressources partagûˋes.
III-B. Architecture centralisûˋe û serveurs multiples▲
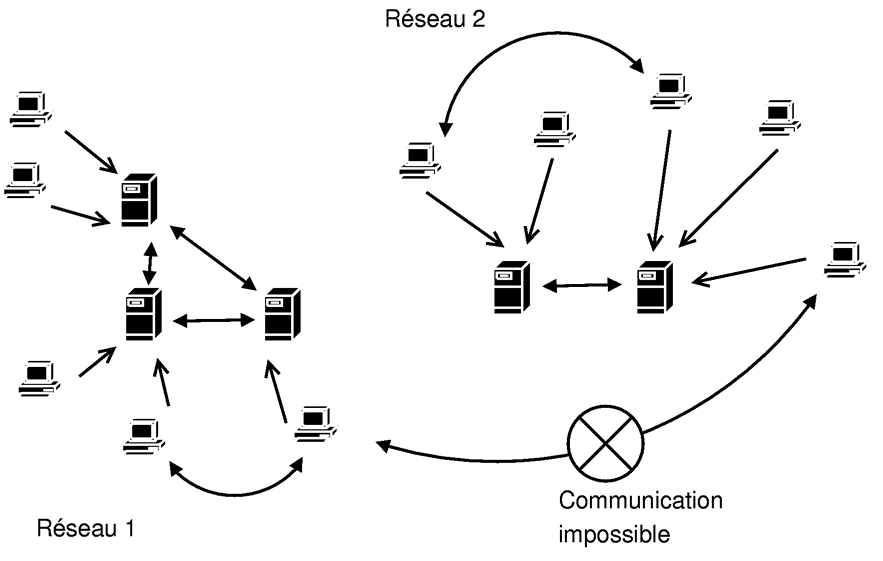
Afin de pallier les dûˋficiences introduites par un unique serveur, une amûˋlioration consiste û remplacer le serveur central par un rûˋseau de serveurs. L'exemple le plus connu est sans doute le rûˋseau eDonkey.
Dans ce type de rûˋseau, on diffû´re encore une fois trû´s bien les serveurs des clients. Ce sont d'ailleurs deux programmes totalement distincts.
Le serveur est, encore une fois, une machine puissante, (gûˋnûˋralement) dûˋdiûˋe û faire tourner le programme (non pas que le programme soit lourd, mais les requûˆtes des utilisateurs oui). Tout le problû´me d'un serveur est de se faire connaûÛtre du public.
Les serveurs sont ensuite en mesure de se connecter entre eux, en fonction de leur connaissance les uns des autres. On peut donc avoir plusieurs rûˋseaux indûˋpendants (CF figure ).
Lorsqu'un client lance le logiciel, il est alors obligûˋ de choisir un serveur auquel se connecter. Pour cela, il doit connaûÛtre au moins un serveur. Des listes de serveurs sont donc disponibles sur le NET, tout le problû´me rûˋsidant alors dans le fait de choisir le bonãÎ
Pour ce faire, le logiciel client permet de disposer d'une description de chaque serveur avec son nom, son IP, une description (faite par le propriûˋtaire du serveur), le ping, le nombre d'utilisateurs, le nombre maximal d'utilisateurs et le nombre de fichiers partagûˋs.
III-B-1. Un exemple d'architecture û serveurs multiplesô : le rûˋseau eDonkey▲
Ce rûˋseau, dont le but est de permettre le partage de gros fichiers multisources dispose de deux rûˋseaux de pairsô : les clients et les serveurs. Un serveur connaûÛt la localisation des documents contenus chez les clients qui sont connectûˋs û lui, alors que le client va stocker des morceaux de fichiers.
Les fichiers
les fichiers sont identifiûˋs de maniû´re unique grûÂce û l'algorithme MD4 (2) sur les serveurs de localisation.
Afin de permettre un meilleur partage des fichiers, ceux-ci sont divisûˋs en segments de 9 Mo chacun. Dû´s qu'un segment est complet, celui-ci est partagûˋ par le client.
Ce systû´me permet d'obtenir un plus grand nombre de personnes disposant du fichier, le rendant ainsi plus facile û obtenir, puisqu'une autre fonctionnalitûˋ d'eDonkey est le tûˋlûˋchargement depuis plusieurs sources.
Un dernier point intûˋressant est la propagation des sources entre les clients.
Supposons que l'on ait 3 clientsô : 1, 2 et 3. 1 et 2 sont sur le mûˆme serveur, et 3 sur un autre. Enfin, 3 dispose d'un gros fichier (mettons 90 Mo) que voudront 2, puis 1.
- 2 effectue une requûˆte.
- Le serveur rûˋpond que 3 dispose de la ressource.
- 2 demande le fichier û 3, le tûˋlûˋchargement commence.
- Dû´s que 2 dispose d'un segment complet du fichier (9 Mo consûˋcutifs), il prûˋvient son serveur qu'il dispose de la ressource ô¨ô fichierô ô£.
- 1 demande û son tour le fichier.
- Le serveur lui rûˋpond que 2 en dispose.
- 1 demande le fichier û 2.
- 2 envoie le fichier et prûˋvient 1 que 3 dispose ûˋgalement de la ressource.
- 1 va donc ûˋgalement demander û 3 des segments du fichier, afin de tûˋlûˋcharger plus vite. û ce moment-lû , on a donc 1 qui tûˋlûˋcharge chez 2 et 3, et 2 qui tûˋlûˋcharge chez 3. Mais rien ne dit que 3 va envoyer les mûˆmes donnûˋes û 2 et û 1. Il se peut donc que 1 dispose de segments souhaitûˋs par 2.
- Donc 2 va ûˋgalement demander û 1 le fichier.
Point de vue du serveur
Comme en mode client/serveur, les serveurs disposent ici de logiciels spûˋcifiques permettant aux clients de se connecter explicitement.
Afin de faciliter le choix du client, le logiciel permet de voir plusieurs informations û propos du serveur, comme le nom ou le ping, mais aussi des informations plus spûˋcifiques comme le nombre de clients maximum, le nombre de clients connectûˋs, ou encore le nombre de fichiers partagûˋs.
Les serveurs ne sont pas directement reliûˋs entre eux, comme c'est le cas d'autres types de rûˋseaux (Kazaa par exemple). En revanche, les serveurs s'ûˋchangent, entre autres, la liste des serveurs connus.
En revanche, cûÇtûˋ client, le fait d'ûˆtre connectûˋ û un unique serveur n'est pas aussi limitant qu'on pourrait le croire. En effet, chaque client demande des IP sources (c'est-û -dire les adresses IP des personnes ayant la ressource recherchûˋe) û l'ensemble des serveurs qu'il rûˋpertorie. Cette possibilitûˋ d'interroger tous les serveurs peut aussi ûˆtre utilisûˋe lors d'une recherche. Derniû´re prûˋcisionô : un client ne publie la liste des fichiers qu'au serveur auquel il est connectûˋ. (3)
Le client
û l'instar de la plupart des autres p2p citûˋs ici, il n'existe pas un unique logiciel pour se connecter au rûˋseau eDonkey. On peut par exemple citer eDonkey(http://www.edonkey2000.com) ou eMule (http://www.emule-projet.net), qui est un peu son pendant franûÏais (avec d'autres fonctionnalitûˋs ûˋgalement), mais aussi des projets moins attendus comme MLDonkey (http://www.nongnu.org/mldonkey/), dûˋveloppûˋ par l'INRIA (4) pour dûˋvelopper les langages fonctionnels (5) .
III-C. Architectures dûˋcentralisûˋes▲
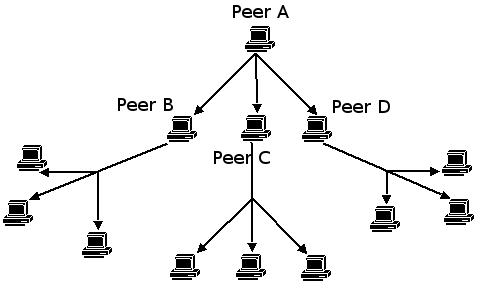
Une autre architecture de P2P est l'architecture dûˋcentralisûˋe. Gnutella est un des reprûˋsentants de cette architecture P2P.
Ici, plus de serveurs au sens communô : tout le monde est û la fois client et serveur. Cela pose principalement un problû´me qui n'apparaûÛt pas avec une architecture centralisûˋeô : comment connaûÛtre la topologie du rûˋseauô ?
Lorsqu'un client souhaite se connecter, il va donc ûˆtre nûˋcessaire d'envoyer un message broadcast (6) afin de savoir quelles autres personnes du rûˋseau sont actives. Seules ces personnes rûˋpondront au message broadcast. On est alors connectûˋ au rûˋseau.
Afin de garder des informations cohûˋrentes, un utilisateur n'est pas connectûˋ directement û plus de 3 ou 4 néuds, et la hauteur d'arbre (7) est gûˋnûˋralement de 7.
Lors des recherches, chaque néud propage la requûˆte û ses voisins (gûˋnûˋralement 4), qui font de mûˆme. Le nombre de propagations est toutefois limitûˋ (gûˋnûˋralement 7), et il est possible de dûˋtecter les cycles grûÂce û l'identificateur des paquets.
III-C-1. Principes sous-jacentsãÎ▲
Ces rûˋseaux reposent sur les principes sous-jacents suivantsô :
- Principe d'ûˋgalitûˋ entre les néudsô :
o Mûˆme capacitûˋ (puissance, bande passanteãÎ),
o Mûˆme comportement (û la fois client et serveur),
o Bon comportement (pas de ô¨ô mensongeô ô£)ô ; - Principe de requûˆtes ô¨ô populairesô ô£ô :
o Les ressources demandûˋes sont beaucoup rûˋpliquûˋes,
o La plupart des requûˆtes ne concernent que peu de ressourcesô ; - Principe de topologie du rûˋseauô :
o Graphe minimisant le nombre de chemins entre deux néuds o La longueur du chemin minimum entre deux néuds est faible (5 û 8) (8) .
III-C-2. ãÎ et rûˋalitûˋs▲
-
Principe d'ûˋgalitûˋ entre les néuds
-
L'article de S. Saroiu et al. [ (9) ] publiûˋ en 2002 montre que l'ûˋcart dans la bande passante disponible peut varier de 1 û 5ô ! Il est d'ailleurs probable qu'avec les connexions Internet disponibles actuellement, cet ûˋcart aura plus tendance û se creuser qu'û diminuer.
- Risque de perturbation du rûˋseau et de partitionnement (trop forte charge demandûˋe û des néuds connectûˋs par modem RNIS par exemple).
- Ce mûˆme article tend û montrer des comportements de client ou de serveur, mais en tout cas pas ou peu de comportement û la fois client et serveur.
-
De mûˆme, Adar et Hubermann [ (10) ] montrent que 70ô % des utilisateurs ne partagent aucun fichier (ou des fichiers inintûˋressants), et que 50ô % des rûˋsultats sont produits par 1ô % des néuds.
- Aucun intûˋrûˆt pour ceux qui partagent (pas de rûˋciprocitûˋ).
- le rûˋseau devient sensible aux fautes et aux attaques.
- Certains néuds font exprû´s de sous-ûˋvaluer leur bande passante, afin de ne pas ûˆtre choisis.
-
-
Principe des requûˆtes populaires
- Les 100 requûˆtes les plus frûˋquentes sont distribuûˋes uniformûˋment.
- Les autres suivent une distribution de type Zipf (11)
- Les techniques de cache des rûˋsultats s'appliquent bien, et sont en mesure d'apporter une amûˋlioration notable.
-
Principe de topologie du rûˋseau
- Plusieurs ûˋtudes montrent que le graphe sous-jacent de Gnutella est de type Small World, et que le degrûˋ des néuds suit une distribution Power Law.
- Le principe de diffusion de Gnutella ne s'adapte pas û SW (beaucoup de messages redondants).
Avantages
- La taille d'un tel rûˋseau est thûˋoriquement infinie, contrairement aux autres architectures dont le nombre de clients dûˋpend du nombre et de la puissance des serveurs.
- L'utilisation d'un tel rûˋseau est anonyme, c'est-û -dire qu'il est impossible d'y repûˋrer quelqu'un volontairement.
- Rûˋseau trû´s tolûˋrant aux fautes
- S'adapte bien û la dynamique du rûˋseau (allûˋes et venus des pairs)
Inconvûˋnients
- Gros consommateur de Bande passante
- Pas de garantie de succû´s ni d'estimation de la durûˋe des requûˆtes
- Pas de sûˋcuritûˋ ni de rûˋputation (pas de notion de qualitûˋ des pairs ni des donnûˋes fournies).
- Problû´me du free-riding (personnes ne partageant pas de fichiers)
III-C-3. Un exemple de rûˋseau dûˋcentralisûˋô : Gnutella▲
|
Types |
Description |
Information |
|
Ping |
Annonce la disponibilitûˋ, et lance une recherche de pair |
Vide |
|
Pong |
Rûˋponse û un ping |
IP et Nô¯ de port.Nombre et taille des fichiers partagûˋs |
|
Query |
Requûˆte |
Bande passante minimum demandûˋe Critû´res de recherche |
|
QueryHit |
Rûˋponse û query si on possû´de la ressource |
IP + Nô¯ de port + Bande Passante.Nombre de rûˋponses + descripteur |
|
Push |
Demande de tûˋlûˋchargement pour les pairs derriû´re un firewall |
IP du pairô ; index du fichier demandûˋ. Adresse IP + Nô¯ de port oû¿ envoyer le fichier |
Ajout d'un néud
Nous supposons ici que le pair A souhaite se connecter au rûˋseau Gnutella. Afin de rendre les schûˋmas plus lisibles, nous limitons le nombre de pairs û 5 (et donc aussi le nombre de propagations). Pour se faire, il va tout d'abord ûˋmettre un message ping (en traits pleins rouges sur la figure ). Ici, celui-ci est d'abord reûÏu par B, qui va alors faire deux chosesô :
- Rûˋpondre û A un message pong (en tirets noirs pour B, en ô¨ô tirets pointô ô£ orange pour D, ô¨ô tirets point pointô ô£ pour C et pointillûˋs pour E).
- transfûˋrer le message de A vers les deux clients qu'il connaûÛt, C et D.
Ceux-ci rûˋpû´tent alors la mûˆme chose (sauf si le nombre de propagations a dûˋjû ûˋtûˋ atteint).
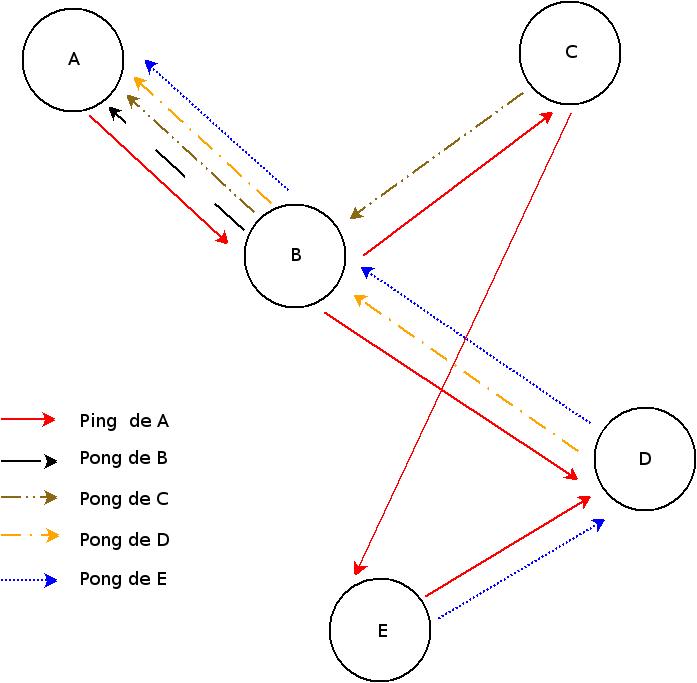
A va donc connaûÛtre les néuds B, C, D et E. On peut d'ailleurs remarquer que E connaûÛt l'existence de A grûÂce û C et û D, mais qu'il ne rûˋpond qu'une fois (via le chemin le plus court, ou le premier qui l'a contactûˋ).
Recherche
Dans cet exemple, A cherche û obtenir le fichier a.txt, disponible chez C et E (ce que A ne sait pas bien ûˋvidemment).
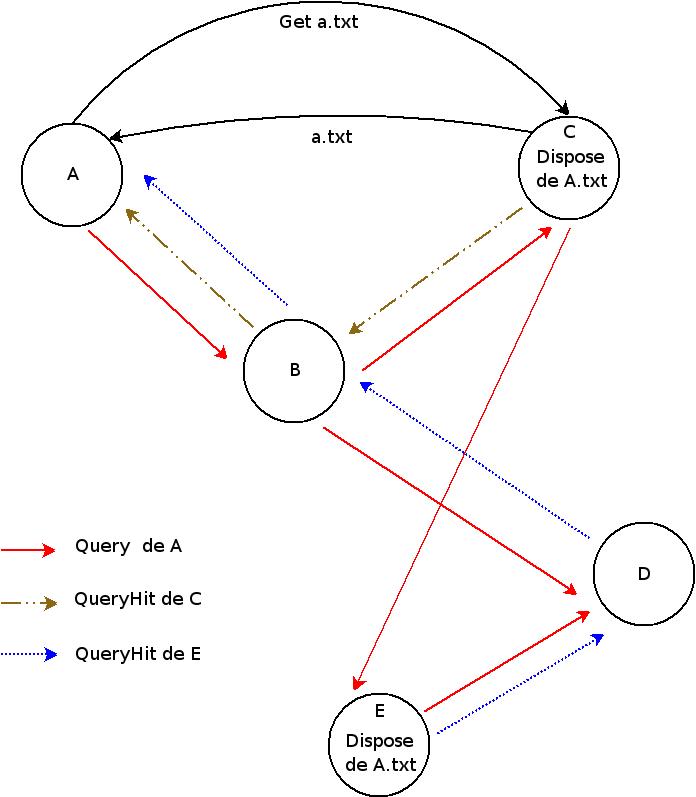
û va donc envoyer un message Query (traits pleins rouges) au(x) premier(s) néud(s) qu'il connaûÛt (ici B), qui se charge
- De rûˋpondre s'il dispose de la ressource (ce qui n'est pas le cas)ô ;
- De propager la question.
Les autres néuds font pareil, ce qui conduit C û rûˋpondre et û propager la requûˆte. A peut alors envoyer û C le message get a.txt, et le transfert peut alors commencer.
Observation de la Bande passante
-
Sur une pûˋriode d'un moisô :
- o La taille d'une requûˆte typique est de 560 bits (y compris headers TCP/IP)
- o Les requûˆtes occupent 25ô % du trafic, les ping 50ô %
- o En moyenne, un pair est connectûˋ activement û trois autres (sur le schûˋma 5, B est un pair typique).
- Du point de vue de la bande passante, Gnutella ne passe pas û l'ûˋchelle.
III-C-4. Un autre exempleô : Freenet▲
Freenet est un logiciel de P2P dûˋcentralisûˋ, dont le but est la diffusion de fichiers de faûÏon totalement anonyme. Ainsi, les donnûˋes ne sont pas tûˋlûˋchargûˋes directement d'un pair û un autre, mais peuvent transiter par un ou plusieurs pairs. Il est ainsi quasiment impossible de dûˋterminer l'origine exacte d'un message. Afin de protûˋger les hûˋbergeurs, tous les fichiers sont cryptûˋs. Le possesseur d'un néud ne peut donc pas connaûÛtre le contenu des fichiers stockûˋs sur son néud. Attention, il est illûˋgal de possûˋder des fichiers ayant un contenu contraire û la loi. Dans la mesure oû¿ le but de freenet est de garantir un anonymat maximal, les mûˋcanismes de routage sont assez complexes, et ne seront donc pas traitûˋs ici. On trouve de trû´s bons documents û ce sujet sur l'Internet ([ (12) ] par exemple). Il suffit juste de savoir que si le néud 1 cherche une information, il demandera û son voisin (appelons-le 2) qui, s'il ne dispose pas de la ressource, transmettra la requûˆte û 3, et ainsi de suite.
Faiblesses de ce rûˋseau
Freenet dispose de nombreuses faiblesses, par exempleô :
- Temps de rûˋcupûˋration d'un fichier Le temps nûˋcessaire pour trouver un fichier dans Freenet reste trû´s honorable. En revanche, le temps de rûˋcupûˋration est beaucoup plus long, û cause des problû´mes d'anonymatô : afin de ne pas connaûÛtre la source du fichier, celui-ci sera copiûˋ sur tous les néuds intermûˋdiaires de la requûˆte.
- Diffusion des clefs Freenet utilise des clefs, notamment pour permettre d'identifier les fichiers. Une recherche de fichier sans cette clef ûˋtant quasiment impossible, il faut que la personne disposant d'un fichier dispose d'un moyen de diffuser la clef. Or si on envisage un site web, cela implique un serveur centralisant les donnûˋes, ce qui va û l'encontre de l'esprit de freenet, û savoir la dûˋcentralisation totale. Il est actuellement possible d'hûˋberger un site web sur freenet (donc sans offrir de serveur fixe), mais dans ce cas lû , on revient au premier problû´me (temps de rûˋcupûˋration) pour chaque pageãÎ
-
Attaques possibles Comme nous l'avons vu, chaque fichier est identifiûˋ par une clef. Ainsi, en gûˋnûˋrant alûˋatoirement un grand nombre de clefs, l'attaquant aura de fortes chances d'obtenir une clef proche de celle du fichier cible. En insûˋrant d'ûˋnormes fichiers avec ces clefs, les néuds ayant des chances de disposer du fichier cible vont ûˆtre saturûˋs. Ensuite, en rûˋalisant de trû´s nombreuses requûˆtes sur les clefs insûˋrûˋes, l'attaquant pourrait corrompre de nouveaux néuds. Pour pallier ces dûˋfaillances, diffûˋrentes solutionsô :
- Identifier les nouveaux néuds avec des clefs proches de celles de néuds chargûˋs, afin de rûˋpartir la charge.
- Changer la politique de gestion des fichiers en local (prendre en compte la prûˋsence ou non d'une copie sur le rûˋseau).
- Disperser sur le rûˋseau des fragments de fichiers, dans le but de pouvoir reconstruire le fichier original plus facilement. Des logiciels comme IBP (13) peuvent apporter beaucoup.
Conclusions sur Freenet
Freenet n'est pas le logiciel P2P le plus simple d'accû´sô : la mise û disposition de fichiers reste complexe, et les recherches de fichiers fastidieuses (proximitûˋ sûˋmantique de la clef)ô ; en outre, les temps de tûˋlûˋchargement sont trû´s trû´s supûˋrieurs û ses concurrents. En revanche, les fichiers sont cryptûˋs, et la source de tûˋlûˋchargement est inconnue du destinataire (et quasiment introuvable), assurant ainsi une grande sûˋcuritûˋ et de l'anonymat. Le choix d'utiliser Freenet ou non va donc dûˋpendre des attentes de chacun.
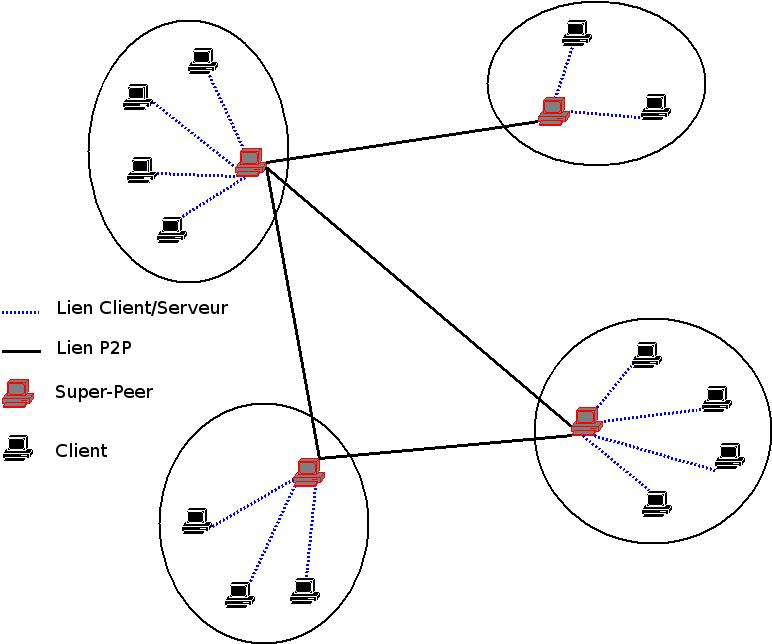
III-D. Une architecture hybrideô : les super-peer▲
III-D-1. Gûˋnûˋralitûˋs▲
Il s'agit ici d'un modû´le que l'on pourrait qualifier d'hybride entre le mode client/serveur et le P2P. En effet, tous les néuds ne sont plus ûˋgauxô :
- Les néuds disposant d'une bonne bande passante sont organisûˋs en P2P. Ce sont les super-peersô ;
- Les néuds avec une faible bande passante sont reliûˋs en mode client/serveur û un super-peerô ;
- Les super-peers disposent d'un index des ressources de leur clusterô ;
Le logiciel de P2P le plus connu utilisant cette technologie est sans doute Kazaa.
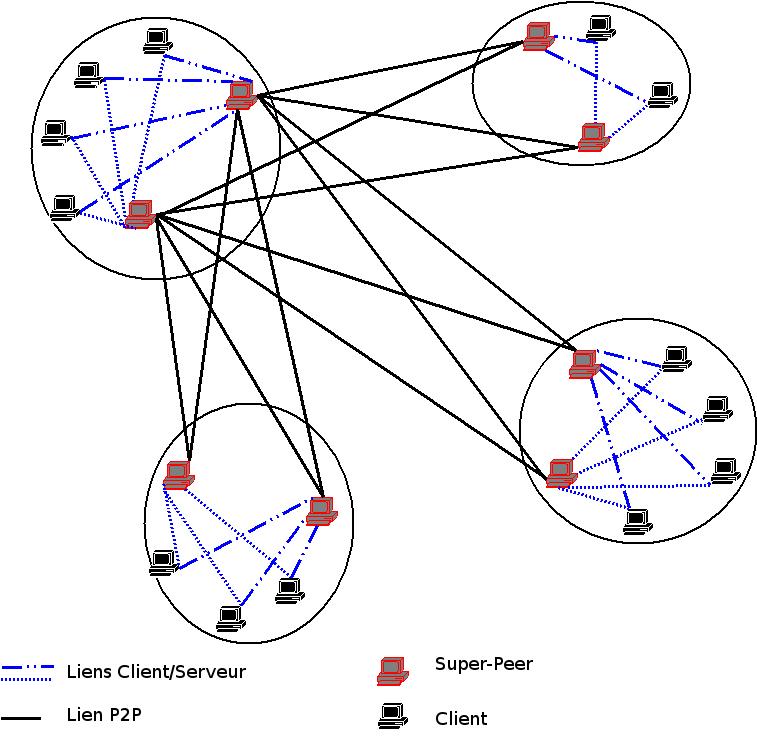
III-D-2. Les super-peer redondants▲
Le choix d'un super-peer introduit de la sensibilitûˋ aux dûˋfaillancesô : si le super-peer n'est plus joignable, tous ses clients sont coupûˋs du rûˋseau. Une des amûˋliorations possibles est donc de choisir parmi K super-peers au lieu d'un seul. Une restriction est que les super-peers soient partenaires. Dans ce cas, chaque partenaire est reliûˋ û chaque client, et possû´de un index de toutes leurs ressources. Les clients envoient leurs requûˆtes selon le principe du Round Robin (14) , ce qui permet de faire baisser la charge d'un facteur k. En revanche, la charge du coû£t d'entrûˋe d'un nouveau client est multipliûˋe par K, et le nombre de connexions ouvertes de Kôý, comme le montre le graphique .
III-D-3. Rû´gles de conception d'un super-peer▲
Pour plus d'informations, il est vivement conseillûˋ de lire [ (15) ], qui dûˋcrit bien plus prûˋcisûˋment ces rû´gles de conceptionô :
- Augmenter la taille d'un cluster diminue la charge agrûˋgûˋe, mais augmente la charge individuelle.
- La redondance de super-peer est favorable.
- Il faut maximiser le nombre de connexions des super-peers (permet de diminuer le nombre de sauts pour atteindre un rûˋsultat).
- Il est nûˋcessaire de minimiser le TTL (16) .
III-D-4. Un exemple de rûˋseau super nodalô : Kazaa▲
Bien que les dûˋtails de fonctionnement de Kazaa ne soient pas entiû´rement divulguûˋs, on sait que ce logiciel utilise une technique de super-peer. En outre, il s'intûˋresse aussi au problû´me de la qualitûˋ des néuds (fiabilitûˋ des informations, mais aussi taux et vitesse d'uploadãÎ)
Principes de Kazaa
Un nouvel utilisateur doit ouvrir un compte, dûˋclarer ses rûˋpertoires de fichiers partagûˋs. En fonction de sa bande passante, le logiciel dûˋcidera si le client est ou non un super-peer (possibilitûˋ de l'activer ou de le dûˋsactiver manuellement). Une incertitude rû´gne quant û la faûÏon de connecter deux super-peer ensembles. Il se peut que ce soit grûÂce û un protocole dûˋcentralisûˋ de type broadcast. Lors d'une recherche, un néud envoie sa requûˆte û son super-peer (il lui transmet en mûˆme temps un index de ses fichiers partagûˋs). Le super-néud dispose d'un index des ses propres ressources, ainsi que celle des néuds de son cluster, ce qui lui permet de rûˋpondre û la requûˆte. Les files d'attente sont paramûˋtrûˋes en fonction de plusieurs critû´res, dont le ratio upload/download et la qualitûˋ des ressources.
III-E. Seti@home▲
Dans la plupart des articles sur le P2P, on retrouve quelque part un paragraphe concernant le projet Seti@home. Je tiens û prûˋciser qu'il n'y a aucune raison de rapprocher ce projet du P2P. En effet, il y a un serveur centralisûˋ, qui communique indûˋpendamment avec chacun des utilisateursô ; ceux-ci sont incapables de communiquer entre eux. On a donc bien affaire ici û un programme fonctionnant typiquement sur le mode client/serveur. Merci de votre attention.
IV. Le P2P sûˋmantique▲
Bien qu'ûˋtant encore au stade de la recherche, le P2P sûˋmantique nous semblait intûˋressant û prûˋsenter ici. Il ne s'agit plus ici de s'intûˋresser û une architecture ou û un programme prûˋcis, puisque la notion de P2P sûˋmantique peut s'appliquer û toutes les architectures et tous les programmes prûˋcitûˋs (selon des changements plus ou moins importants). Le principe est d'ajouter de l'information dynamique aux tables de routage. Cette information peut ûˆtre gûˋnûˋraliste, ou bien au contraire trû´s spûˋcifique, en fonction des besoins. Un des problû´mes est de chercher û trouver un ûˋquilibre entre taille et prûˋcision.
IV-A. Quelle information ajouter▲
On peut ajouter de l'information sur trois points particuliersô : le contenu des néuds, les requûˆtes ou encore les utilisateurs.
-
Sur le contenu des néuds
-
Sur les requûˆtes
- Suppose peu de requûˆtes diffûˋrentes
- Le routage se fait alors en comparant deux requûˆtes.
-
Sur les utilisateurs
- Suppose que les utilisateurs ont toujours les mûˆmes besoins
- Routage en comparant les utilisateurs entre eux.
- On peut enfin avoir un mûˋlange de ces trois solutions.
IV-B. Routing Indices▲
Le but des indices de routage, comme expliquûˋ dans [ (19) ] est d'introduire de l'information sur le contenu des néuds (index). Dans ce sens, c'est un systû´me analogue aux systû´mes d'indices rûˋpartis et hiûˋrarchisûˋs pour les moteurs de recherche sur l'Internet.
|
Chemin |
Nombre de documents |
BDD |
Langages |
Rûˋseaux |
Thûˋorie |
|
B |
100 |
20 |
30 |
0 |
10 |
|
C |
1000 |
0 |
50 |
300 |
0 |
|
D |
200 |
100 |
150 |
0 |
100 |
Table 1: Exemple de Routing Indices pour le néud A
Le tableau 1 se lit de la faûÏon suivanteô :
B peut accûˋder û 100 documents, dont 20 traitent de BDD, 30 de langages et 10 de thûˋorie.
D accû´de û 200 documentsô : 100 concernent les BDD, 150 les langages, et 100 la thûˋorie.
Dans la mesure oû¿ ce tableau reprûˋsente les informations pour le néud A, on peut en conclure que ce néud est en mesure d'accûˋder û 1 300 documents (attention, ils ne sont pas forcûˋment diffûˋrents, puisque B, C D ainsi que leurs fils n'ont pas de liaisons directes), dont 120 traitent de BDD, 230 de langages, 300 de rûˋseaux et 110 de thûˋorie.
Cet exemple nous montre bien que tous les documents n'apparaissent pas forcûˋment dans une catûˋgorieô : B permet d'accûˋder û 100 documents, dont seulement 60 sont rûˋpertoriûˋs dans les domaines citûˋs. Qu'un document peut couvrir deux domaines, et donc ûˆtre rûˋpertoriûˋ deux fois. C'est ici le cas pour le néud D. Plus concrû´tement, un document traitant de la thûˋorie du langage SQL sera rûˋpertoriûˋ en ô¨ô thûˋorieô ô£, en ô¨ô langagesô ô£, et en ô¨ô BDDô ô£.
Algorithme de recherche
-
Rûˋsoudre localement la requûˆte Q. S'il n'y a pas suffisamment de rûˋsultatsô :
- ûvaluer la proximitûˋ des successeurs
-
Tant qu'il n'y a pas assez de rûˋsultats
- Prendre le successeur S le plus proche
- Recherche (Q, S)
- Retourner les rûˋponses
Performances de la recherche
- Le nombre de messages est diminuûˋ par rapport û l'algorithme de recherche de Gnutella
- L'exploration est restreinte aux néuds ayant la plus grande probabilitûˋ de succû´s
- Pas de garantie d'avoir tous les rûˋsultats
- Pas d'informations sur le nombre de sauts nûˋcessaires (amûˋliorations possibles grûÂce û d'autres RI)
- PlutûÇt orientûˋ recherche des K meilleurs rûˋsultats.
Bilan des RI
- La structure d'indexation est assez simple, mais sa mise û jour (non prûˋsentûˋe ici, mais explicitûˋe dans [ (20) ]) gûˋnû´re beaucoup de messages
- Fonctionne bien pour obtenir les meilleurs rûˋsultats, mais qui ne sont pas forcûˋment tous les rûˋsultats
- Nûˋcessite la dûˋtection (ou la prûˋvention) des cycles (A a pour fils B qui a pour fils C qui a pour fils A)
- Bien pour des langages de type mots-clefs, mais pas gûˋnûˋralisable û des langages plus complexes
- RI ne donne pas d'indications sur le nombre de sauts (mais d'autres oui).
IV-C. SONô : Semantic Overlay Networks▲

L'exemple prûˋsentûˋ sur la figure 10 nous montre 8 néuds classûˋs par genre de musique. Un néud est reliûˋ û un autre par un lien logique de type ni, nj, lk (lire néud i, néud j, lien k). Par exemple, sur le schûˋma, le lien entre A et B estô : û, B, 'Rock'.
Les liens ayant le mûˆme l forment un SON.
Ici, nous avons les SON suivantsô : Rock, avec les néuds A, B et Cô ; Rap, avec B, E, et Fô ; Jazz, avec E, F et Gô ; Techno, avec F, D et Hô ;
Un SON avec un seul label est un P2P classique. On peut ûˋgalement remarquer que lorsque le SON a ûˋtûˋ choisi, suite û une requûˆte, alors on retombe une nouvelle fois sur un P2P classique.
Encore une fois, le plus gros problû´me vient de la dûˋfinition sûˋmantiqueô : comment dûˋfinir le SONô ?
Pour ce faire, on peut imaginer un style (musique) avec des sous-styles (Rock, JazzãÎ) comprenant eux-mûˆmes d'autres sous-styles (Pop, Rock'n Roll, indûˋpendantsãÎ pour Rock par exemple).
Une bonne hiûˋrarchie de classification demandeô : des classes dont les documents appartiennent û un petit nombre de néuds. Que les néuds se trouvent dans peu de classes. Des classificateurs faciles û construire et les plus fiables possible.
Rûˋsolution d'une requûˆte
Il faut tout d'abord chercher les concepts correspondants û la requûˆte, puis ensuite propager cette derniû´re dans le SON correspondant, ainsi qu'û ses ascendants et descendants.
Bilan des SON
Ces rûˋseaux reposent avant tout sur la classification des documents. Celle-ci est relativement complexe û mettre en éuvre, et est surtout liûˋe û un domaine prûˋcis. Il est d'envisager des SON ayant trait û des domaines divers, mais d'autres problû´mes surgissent alors.
Les SON favorisent la prûˋcision, mais pas la complûˋtude.
Du point de vue technique, on peut tout û fait parallûˋliser les SON afin d'obtenir des temps de rûˋponse meilleurs (les requûˆtes sont alors lancûˋes dans chacun des SON sûˋlectionnûˋs par un classificateur).
Les rûˋsultats expûˋrimentaux montrent une amûˋlioration notable du nombre de messages comparativement û Gnutella.
V. Problû´mes ouverts dans la recherche sur les P2P▲
Un problû´me ouvert est un problû´me auquel on n'a pas encore trouvûˋ de solution, et auquel on est susceptible d'en trouver une (21) .
-
Sûˋcuritûˋ
- Disponibilitûˋ
- Authentification des ressources (si plusieurs sources pour une ressourceô : plus vieille ressource (probabilitûˋs que ce soit l'originale, et donc une version plus ô¨ô authentiqueô ô£)), rûˋputation des pairs, vote
- Anonymat de l'auteur du document (CF authentification), des serveurs (quels documents sont sur un serveur donnûˋ), du lecteur, et des documents (sur quel néud est un document prûˋcis).
- Rûˋputation
- ContrûÇle du Free-Riding
- Tables de hachage dynamiques
- P2P Sûˋmantiqueô : ce n'est que le dûˋbut. On peut explorer par exemple le mûˋlange de diffûˋrentes technologies, ou bien encore chercher û introduire des connaissances dynamiques, comme l'apprentissage (modifications de diffûˋrents paramû´tres en fonction des observations menûˋes sur le rûˋseau).
VI. Utilisations du P2P▲
VI-A. Calculer▲
Le P2P permet de mettre en commun de nombreux ordinateurs, disposant chacun de ressources limitûˋes. Mais en ô¨ô additionnantô ô£ les ressources de chacun, on obtient des performances thûˋoriques gargantuesques.
Un exemple parlant aux mathûˋmaticiens est le calcul de matricesô : l'une des mûˋthodes permettant l'inversion des matrices nûˋcessite n3 opûˋrations (n ûˋtant la taille de la matrice (qui comporte donc nôý cases)). Un des challenges actuels est de rûˋaliser un tel calcul grûÂce au P2P, avec n = 10^6 (un million), soit un total de 10^18 (un milliard de milliards) opûˋrations ãÎ (22)
Le but est donc de diviser ce gros calcul qu'est l'inversion de la matrice en petits calculs plus ou moins indûˋpendants que l'on pourra rûˋpartir entre les pairs. Cet algorithme demande cependant d'avoir dûˋjû une partie des informations pour pouvoir continuer. Il faudra donc que les pairs ûˋchangent des donnûˋes afin de pouvoir effectuer de nouveaux calculs.
Toutefois, outre le fait de trouver suffisamment de pairs pour rûˋaliser ce test, d'autres problû´mes surviennentô :
- Les néuds sont volatils, c'est-û -dire qu'ils arrivent et partent quand ûÏa leur plaûÛt. Donc il va falloir confier le mûˆme calcul û plusieurs néuds (notion de clouage).
- Du fait que l'algorithme a besoin des calculs prûˋcûˋdents pour en effectuer de nouveaux, les temps de communication entre deux néuds sont trû´s supûˋrieurs au temps de calcul. Or sans vouloir faire intervenir la rentabilitûˋ ici, le projet ne prûˋsentera que peu d'intûˋrûˆt si les 3/4 du temps sont passûˋs û ûˋchanger des donnûˋes et non û calculer.
- ãÎ
Des solutions sont donc actuellement ûˋtudiûˋes afin de rûˋaliser de grands calculs grûÂce au P2P. On peut citer, entre autres projetsô :
- Chordô : http://www.pdos.lcs.mit.edu/chord/
- Cxô : Transformer votre PC en ressources globales de calcul http://www.cs.ucsb.edu/projects/cx/
- Farsiteô : Stockage de donnûˋes dans un environnement non sûˋcurisûˋ http://research.microsoft.com/sn/Farsite/
- Globeô : Gestion d'objets distribuûˋs http://www.cs.vu.nl/globe/
- OceanStoreô : Stockage massif de donnûˋes http://oceanstore.cs.berkeley.edu/
- Pastryô : Une sous-couche pour les applications P2P http://research.microsoft.com/~antr/Pastry/
- XtremWebô : Calcul scientifique û travers le Webô : http://www.lri.fr/~fedak/XtremWeb/introduction.php3
- ãÎ
VI-B. Diffuser des donnûˋes▲
La diffusion de donnûˋes en utilisant le P2P permettrait de toucher beaucoup plus de personnes avec des moyens bien infûˋrieurs û ceux nûˋcessaires aujourd'hui. Actuellement, si on veut ûˋmettre de la vidûˋo (par exemple), il faut non seulement une machine qui diffuse la vidûˋo (logique), mais ûˋgalement une trû´s trû´s bonne connexionô : plus le nombre de gens est important, plus la connexion doit ûˆtre grosse (23) .
En revanche, en utilisant le P2P, chaque personne devient û la fois rûˋceptrice et ûˋmettrice. Ainsi, le diffuseur initial n'a plus que quelques clients connectûˋs û lui, chacun de ces clients jouant ûˋgalement le rûÇle de diffuseurs pour d'autres clients.
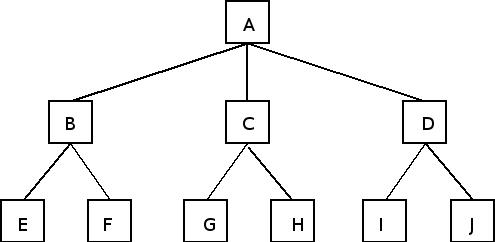
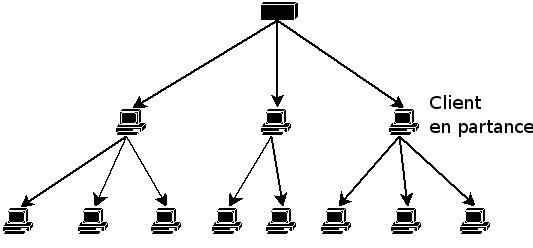
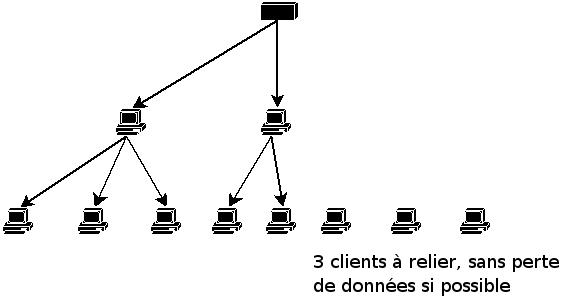
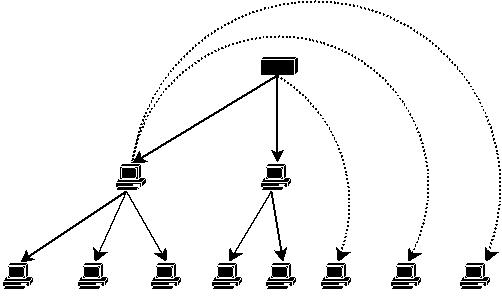
Encore une fois, c'est plus complexe û mettre en éuvre qu'û expliquer, les principaux problû´mes ûˋtant la volatilitûˋ des clients (enfin des serveurs devrais-je dire), qui pose des problû´mes de rattachement des clients, comme le montrent les figures 11, 12 et 13.
VII. Conclusion▲
Dans cet article, j'ai souhaitûˋ mettre en avant le fait qu'il existe diffûˋrents modû´les de P2P, chacun disposant d'avantages et d'inconvûˋnients. Il est donc logique que l'utilisation faite de ceux-ci ne soit pas la mûˆme.
ûtonnamment, la recherche sur les P2P est en retard. En effet, contrairement aux cas plus traditionnels, cette technologie n'est pas issue de la recherche fondamentale, mais a ûˋtûˋ rûˋcupûˋrûˋe par cette derniû´re. C'est pour cette raison qu'on en est qu'au dûˋbut du P2P sûˋmantique, ou mûˆme du calcul P2P, de la diffusion de donnûˋesãÎ
Si vous souhaitez vous renseigner sur ces technologies, le plus simple est encore d'aller voir les sites des projets qui vous semblent intûˋressants, ou de rechercher des informations via un moteur de recherche.
VIII. Sources▲
Ce document est en partie inspirûˋ d'un cours de Bruno Defude, que vous trouverez ici.
Les autres sources s'appliquant û des parties plus ciblûˋes du document sont citûˋes dans les notes de bas de page.